Building a bird detector from scratch with web scraping and deep learning (part 1)
Posted on di 21 januari 2020 in Projects

This is part 1 in a series on this project, more posts will be written as the project progresses
I'm an awful birder. While I've always been interested in birds I'm almost completely deaf to identifying them by their calls. I never started memorizing them and my ability to recognize them on the basis of visual cues is poor. It was only when I started kayaking (about five years ago) that I was exposed to more bird-watching, and during a trip to Schotland last year a couple of friends took me on my first bird watching trip.
So given that my human-based detection is obviously lacking I figured that with the plethora of bird data online, would it perhaps not be possible to scrape these and create a bird classifier using CNNs and general Python shenanigans?
Intro
I also wanted to make a funny trinket out of this and deploy it to a Pi. I'm lucky to have family that live on a farm in a rural area and have multiple feeding stations for the birds. Apart from the 30-or so bird species that they've actively tracked over the past year, there are also chickens, hedgehogs, mice, rats, and various predators like hawks and foxes that drop by. Some of the feeding stations are viewable from indoors, while others are between trees and bush. This will be the testing ground.
This is actually a very active research topic in the past couple of years, as ecologists, population biologists and researchers are using deep learning to automate detection. Consider that according to a May 2018 paper, roughly one third of papers on this subject was published in 2017 and 2018 [1]. Focus is particular on video and audio (e.g. bird calls).
As for approaches, it seems that my idea of CNNs and Pis is spot on. [2] Shows a CNN model with skip connections traind on 27 bird species in Taiwan can approach 99% accuracy. There is also another source that shows it is possible to use a Raspberry Pi for classification amongst three species [3]. And that's just scraping the surface: more advanced models are being developed. Further inspiration comes from Ben Hamm and his cat Metric [4]:
One particular website that's a huge hub for biologists and bird-watchers is the Dutch site www.waarneming.nl. It's worth mentioning waarneming employs their own suite of models and automatically classifies uploaded photos. In 2019, they received around eight million photos. With this data they've also put out their own deep learning-powered app: Obsidentify.
But why would anyone do this if there's already apps (and with that probably APIs) that do this? For starters, I like the idea and challenge of bringing this end to end. It's a learning experience for me. Secondly, I like to gift this set up to my in-laws at some point so to have some kind of automated tracking when there's something going on in the garden. Scientifically this is a valid topic: bird classification scales poorly as does droning over photos or video streams is a labour-intensive task.
Why is this a hard problem?
While the training data mostly contains photo's of birds zoomed up and resting on a branch, the real-life data is much more messier. Consider this:
- Birds do, in general, not sit still long enough
- There might be multiple birds and multiple species in a single shot
- The size of a birds vary
- Many bird species are dimorphic: males and females look different
- Every bird species has different feeding strategies which result in different images, with some more inclined to frequent a station than others.
- They might be in an odd point of view (e.g. viewing a bird from the rear)
- Training data of the same species from different areas might be too different
- The background (branches, fields) is very different from the feeding stations. Consider the "wolf vs background" problem where an AI system trained to distinguish wolves was actually picking up on the presence of snow in the training image to determine whether the photo was of a wolf or dog instead of the actual subject. This is a valid problem in this context
- There might be a number of branches and foilage in the way of the birds (consider, for instance the header image of this post)
As for actually doing it: - Training a neural network simply requires a ton of labelled data. - There is a huge difference between photos shot with a telescopic lens of say 250mm+ and a wide-angle over the counter camera such as a the pi camera - The quality of these webcams, action cams and the pi-camera might simply be too bad to do this - Some excellent training data might explictely forbid usage (licence) - Some of the images available are simply cell-phone camera shots through a telescope or of a DSLR-display. - In order to adequately classify birds, I have to recognize (a) an image contains a bird (a binary problem), (b) find where in the image the bird is and predict a bounding box around it and (c) classify the bird.
In all, there's a large potential for a miss-match between the training data and the real-world case I'm trying to work on.
Act 1: Identifying training data
Waarneming.nl has photo's publicly available and the data is relatively easy to access. Since the goal environment (a farm in the Netherlands) and the training data environment (most uploads are from Belgium and the Netherlands) are the same, this was my first choice for training data.
There's also Flickr which even publicly exposes an API for these goals. This might be the best / easiest option if you're not looking for data from Europe. eBird seems to be scrape-able the same way. While searching for 'Staartmees' on Flickr yields only about 2000 hits, checking for 'Long-tailed tit' gives around 62.000 photos.
Lastly, there are two datasets that might be of use. First there's the Caltech-UCSD Birds-200-2011 data set of almost 12000 photos and 200 species. This information may be useful later on for detecting a bounding box (a square to identify where in an image a bird is located) around a bird. Similarly, there is the Japanese Wild Birds in a Wind Farm: Image Dataset for Bird Detection data set for detection, although this is again only useful for detection and not classification - an important distinction.
Act 2: Scraping training data
I set out to scrape the data from waarneming.nl as this is the absolute closest to my real-life use case and the image quality is insanely high, being mostly from birders with professional gear. Futhermore, as the data is community-sourced and often verified, I can directly treat the image labels as based in truth (something that would not be possible with say Flickr). I turned to the gallery:
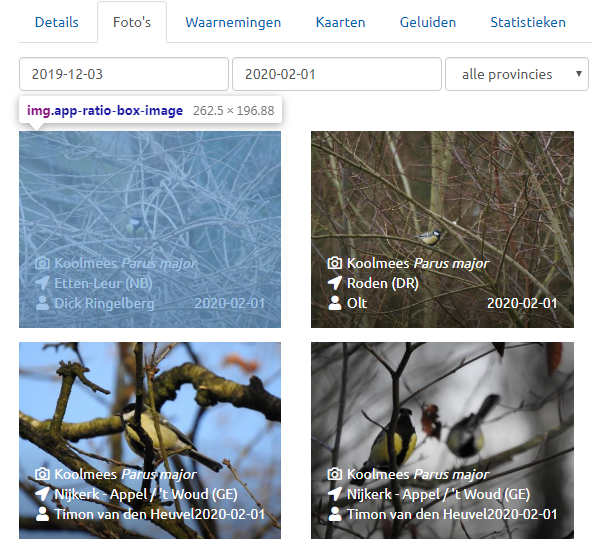
Waarneming has a gallery function that lists 24 bird photos each time. Despite there being more images on the site than the gallery, only the gallery has the app-ratio-box-image class, so this allows us to collect only these links.
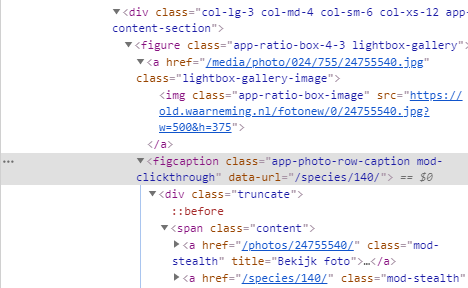
Also note that the html includes links to the image (ending in .jpg) as a page describing an image (ending with photos/<image_id>/. This leads to a page that has meta data on the image - more on that in a bit.
Based on the species list (below) I looked at querying for each specific bird. However, there are many possible species and a simple search might return multiple possible hits (subspecies might be returned). Since I'd have to make a list of each species' latin name anyway, I just searched for an individual species and collected the species' id. I stored these in a dict like below:
{
'species_name': 'species_x',
'id': 1
}
For each species in the list I crawled the site. I could not find a robots.txt that disallowed web scraping and the license found on https://waarneming.nl/tos/ explictely permits non-commercial use by individuls. However, because the strain on a website can be considerable it is a good practise to build in a pause of 1 second between requests. I did not initially do this as I had honestly had not considered the strain on their servers.
The below script accomplishes the main scraping goals. I made use of the beautifulsoup and requests libraries to collect the html from the pages and parse them. I also included a call to check which images I already have downloaded, so I don't waste resources fetching the same image twice.
for i in range(1,int(MAXIMAGES/IMAGESPERPAGE)+1):
# construct the url
URL = 'https://waarneming.nl/species/'+identifier+'/photos/'
'?after_date=2018-01-01&before_date=2020-01-19&page='+str(i)
# fetch the url and content
page = requests.get(URL)
soup = BeautifulSoup(page.content, 'html.parser')
#find the images
tags=soup.findAll('img',{"class":"app-ratio-box-image"})
photolinks += tags
#pause for one second out of courtesy
time.sleep(1)
# get the photoids we already have scraped from before
photoids = get_photoid_list(species)
metadata = []
# download photos and store them in their new home
for link in photolinks:
#url without arguments
url = link['src'].split('?w')[0]
#obtain filename from url
filename = url.split('/')[5]
#check if we have encountered this photo before - will be substantially slower with large n
if filename.split('.')[0] not in photoids:
# we have a new photo, so lets check the metadata first
meta = get_metadata(filename.split('.')[0])
if meta:
meta['photoid'] = filename
metadata.append(meta)
if meta['Licentie'] in ALLOWED_LICENSES:
path = RAWFOLDER+'/'+species+'/'+filename
get_and_store_image(url, path)
#also resize the image and store them seperately
outputpath = PROCESSEDFOLDER+'/'+species+'/'+filename.split('.')[0]+'.png'
convert_and_store_img(path, outputpath)
new_photos += 1
#pause for one second out of courtesy
time.sleep(1)
The above code includes calls to the following methods and variables:
get_photoid_list searches the species directory for any existing photos (because there's no point in downloading the same photo twice if we re-run the script)
ALLOWED_LICENSES contains a list of licences that allow us to scrape.
get_and_store_image requests the image from an url and stores it to local disk
get_metadata requests the page that holds info on a particular photoid and outputs the photo details to a meta object. This way, we can trace which photo's we crawl and who made them, but also the license for an individual photo.
convert_and_store_img changes the photo to a set x by y size and also appends each image so all the training data has the same dimensions.
time.sleep(1) tells the scrape script to pause for one second.
metadata is a list of meta objects I store to disk afterwards.
The attentive reader might notice we're also collecting metadata on images we don't scrape. This is mainly because I want to trace the different licences and other metadata associated with them and to verify that everything works correctly. The metadata is stored to a flat file. Below is the get_metadata call:
def get_metadata(photoid=24691898) -> dict:
'''Given a photo-id, return metadata in a dict'''
url = 'https://waarneming.nl/photos/'+str(photoid)
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
tags=soup.find('table',{"class":"table app-content-section"})
meta = {}
if tags:
# find all table rows
rows = tags.find_all('tr')
values = []
keys = []
# get the table content and return as two lists
for row in rows:
# actual content is listed in the <td>, while <th> holds the keys.
descriptions = row.find_all('th')
cols = row.find_all('td')
for idx, ele in enumerate(descriptions):
keys.append(ele.text.strip())
values.append(cols[idx].text.strip())
#create a dict out of the data we fetched
meta = dict(zip(keys, values))
return meta
...which returns the following:
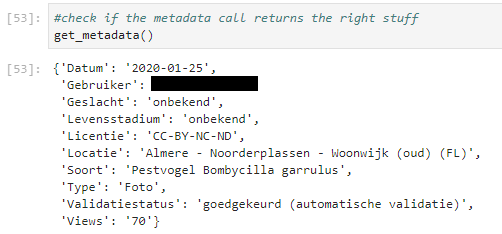
The data is contained in a table, and each row only contains a <th> (header) and <tr> (row). Thus, we obtain the keys from the <th> and the values from information enclosed by the <tr> tags. Note that we fail elegantly: if there's nothing in the table (or the table is not there) we return an empty meta. And if we do not have the meta object explictely stating what kind of value we have for a license, we don't download the photo.
With that, we're all set to start scraping. Let's define what birds we want to look for.
Species list
The below lists the species I collected data about.
| # | Latin NamE | English Name | Dutch Name |
|---|---|---|---|
| 1 | Cyanistes caeruleus | Eurasian blue tit | Pimpelmees |
| 2 | Parus major | Great tit | Koolmees |
| 3 | Aegithalos caudatus | Long-tailed tit | Staartmees |
| 4 | Lophophanes cristatus | European crested tit | Kuifmees |
| 5 | Fringilla coelebs | Common chaffinch | Vink |
| 6 | Turdus merula | Common blackbird | Merel |
| 7 | Sturnus vulgaris | Common starling | Spreeuw |
| 8 | Passer montanus | Eurasian tree sparrow | Ringmus |
| 9 | Passer domesticus | House sparrow | Huismus |
| 10 | Emberiza citrinella | Yellowhammer | Geelgors |
| 11 | Prunella modularis | Dunnock | Heggenmus |
| 12 | Certhia brachydactyla | Short-toed treecreeper | Boomkruiper |
| 13 | Chloris chloris | European greenfinch | Groenling |
| 14 | Sitta europaea | Eurasian nuthatch | Boomklever |
| 15 | Erithacus rubecula | Robin | Roodborstje |
| 16 | Dendrocopos major | Great spotted woodpecker | Grote Bonte Specht |
| 17 | Pica Pica | Magpie | Ekster |
| 18 | Carduelis carduelis | European goldfinch | Putter |
| 19 | Troglodytes troglodytes | Eurasian wren | Winterkoning |
| 20 | Turdus philomelos | Song thrush | Zanglijster |
| 21 | Columba palumbus | Common wood pigeon | Houtduif |
| 22 | Streptopelia decaocto | Eurasian collared dove | Turkse Tortel |
| 23 | Columba Oenas | Stock dove | Holenduif |
| 24 | Motacilla Alba | White wagtail | Witte Kwikstaart |
| 25 | Picus Viridis | European green woodpecker | Groene Specht |
| 26 | Garrulus glandarius | Eurasian jay | Gaai |
| 27 | Fringilla Montifringilla | Brambling | Keep |
| 28 | Turdus Iliacus | Redwing | Koperwiek |
| 29 | Turdus Pilaris | Fieldfare | Kramsvogel |
| 30 | Oriolus Oriolus | Eurasian golden oriole | Wielewaal |
Pre-processing data
In order to re-shape the data into a format that a ML model can interpret I performed the following steps.
1) I Resized the image to have a max dimension of 256 by 256 2) Centered the image and padded the sides wherever it was less than 256 3) Cut a 224 x224 section from the middle of the image
This builds heavily on the python version of the opencv library as well as numpy. The result is a 224 by 224 photo from any input photo.
The resizing of images might not be needed for every possible network, but it might be important to some convolutional architectures. I chose 224 by 224 because these are the dimensions that some of the pre-trained networks available in Keras - such as vgg16 [5] - work with. While it would be massively better for training time to pick a smaller size (say 32x32), the bird is generally only a small portion of the pixels in the image. I fear that if I was to limit the size too aggresively I'd limit the usefulness of my training data too much.
The below code snippet shows how the resizing and centering is done.
def center_image(img):
'''Convenience function to return a centered image'''
size = [256,256]
img_size = img.shape[:2]
# centering
row = (size[1] - img_size[0]) // 2
col = (size[0] - img_size[1]) // 2
resized = np.zeros(list(size) + [img.shape[2]], dtype=np.uint8)
resized[row:(row + img.shape[0]), col:(col + img.shape[1])] = img
return resized
I am actually trimming the edges a little as I figured that the bird in any given photo from this data set is likely in the middle of the photo.
#resize
if(img.shape[0] > img.shape[1]):
tile_size = (int(img.shape[1]*256/img.shape[0]),256)
else:
tile_size = (256, int(img.shape[0]*256/img.shape[1]))
#centering
img = center_image(cv2.resize(img, dsize=tile_size))
#output should be 224*224px for a quick vggnet16
img = img[16:240, 16:240]
The actual scraping
So now I have methods defined for going through the gallery, collecting the links along the way. For each link I store the metadata and look up whether the licence is in my ALLOWED?LICENCES list. Roughly 60% of all photo's are blocked by a licence. If there´s a match I download the image.
With the 30 bird species I defined earlier it´s just a simple list of dicts to go through for scraping. Here bird_scraper takes a bird name (used for constructing a folder) and an id to query with:
for s in species:
bird_scraper(s['name'], s['id'])
# show a random photo to brighten the day
print(str(s['name'])+':')
show_random_img_from_folder(RAWFOLDER+'/'+s['name'])
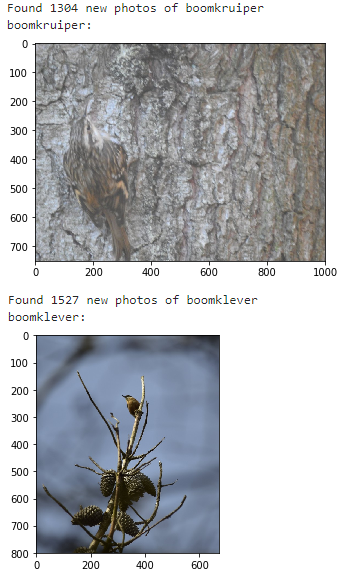
In the end I show a random image from the samples I collected. I figured that this would be a nice screenshot to include because it demonstrates three problems: * The bird versus background problem (when we are training, are we actually modelling the birds or are we overfitting on their habitat?) * The odd angle * The bird itself might only be a very small portion of the photo
Now, let's see how many photos we captured..
Act 3: Results
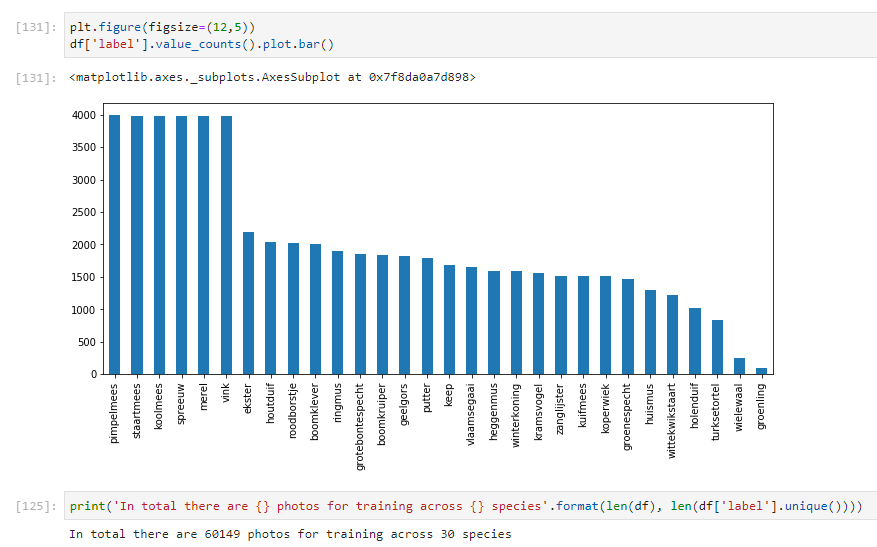
The total number of bird photos I scraped per species is shown in the graph below. Apparently the common birds are all a bit even, while I could not query for more than 90 Groenling photos. This might be a bug or some kind of anti-scraping measure, as I always thought these birds were fairly common.
Discussion
After starting out I decided to limit the scraping to a max of 4000 samples per bird species, which I further brought down by instead of scraping until I had 4000 images going for 4000 images and just using how many images were allowed as training data. That meant that I scraped roughly half of that number. My goal is not to build the best possible system, but only 2000 samples per bird will mean its likely difficult to train a model.
While most data scientists and like will argue that scraping is perfectly legal, the legality of web scraping licenced material is much more a grey area. Roughly 60% of the data is licensed with a 'no derivative' variant or 'all rights reserved'.
In total, my scraping netted in 60.149 usable images across 30 species. While some classes have a ton of samples (also because I started off with requesting more than I needed), others have much less samples available. This skew in the data should probably be addressed while constructing a model in the next post in this series.
Disclaimer: this blog post details a project that's still very much underway. I intend to retrain the models before I deploy the 'final' models and further refine the technique, and then also update this blog post. The header image is one of my own photos and I will strive to include many as my own photos as test data.
This blog post benefited from ongoing discussion with experts from a variety of backgrounds. I would like to thank a number of people: Linde Koeweiden, Jobien Veninga and Johan van den Burg. I would also like to thank the people behind Waarneming for their interest in my project and pointing out issues with my approach.
Papers referenced in this post: [1]: Christin, S., Hervet, E., & Lecomte, N. (2019). Applications for deep learning in ecology. Methods in Ecology and Evolution, 10(10), 1632-1644. [2]: Huang, Y. P., & Basanta, H. (2019). Bird image retrieval and recognition using a deep learning platform. IEEE Access, 7, 66980-66989. [3]: Ferreira, A. C., Silva, L. R., Renna, F., Brandl, H. B., Renoult, J. P., Farine, D. R. & Doutrelant, C. (2019). Deep learning-based methods for individual recognition in small birds. bioRxiv, 862557. [4]: Cats, Rats, A.I., Oh My! - Ben Hamm: https://www.youtube.com/watch?v=1A-Nf3QIJjM [5]: Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.